> ## Documentation Index
> Fetch the complete documentation index at: https://docs.benzinga.com/llms.txt
> Use this file to discover all available pages before exploring further.
# インフラアーキテクチャ
> Benzinga の 99.9% API 可用性を支えるエンタープライズグレードのインフラと、世界水準の監視・信頼性
Benzinga のインフラは **99.9% の可用性** を実現するよう設計されており、アプリケーションが常時、信頼性の高いリアルタイム金融データを受信できるようになっています。本番環境は実運用で実証されており、全面的に監視され、平日24時間(24/5)のオンコールエンジニアリングサポートによって支えられています。
## 概要
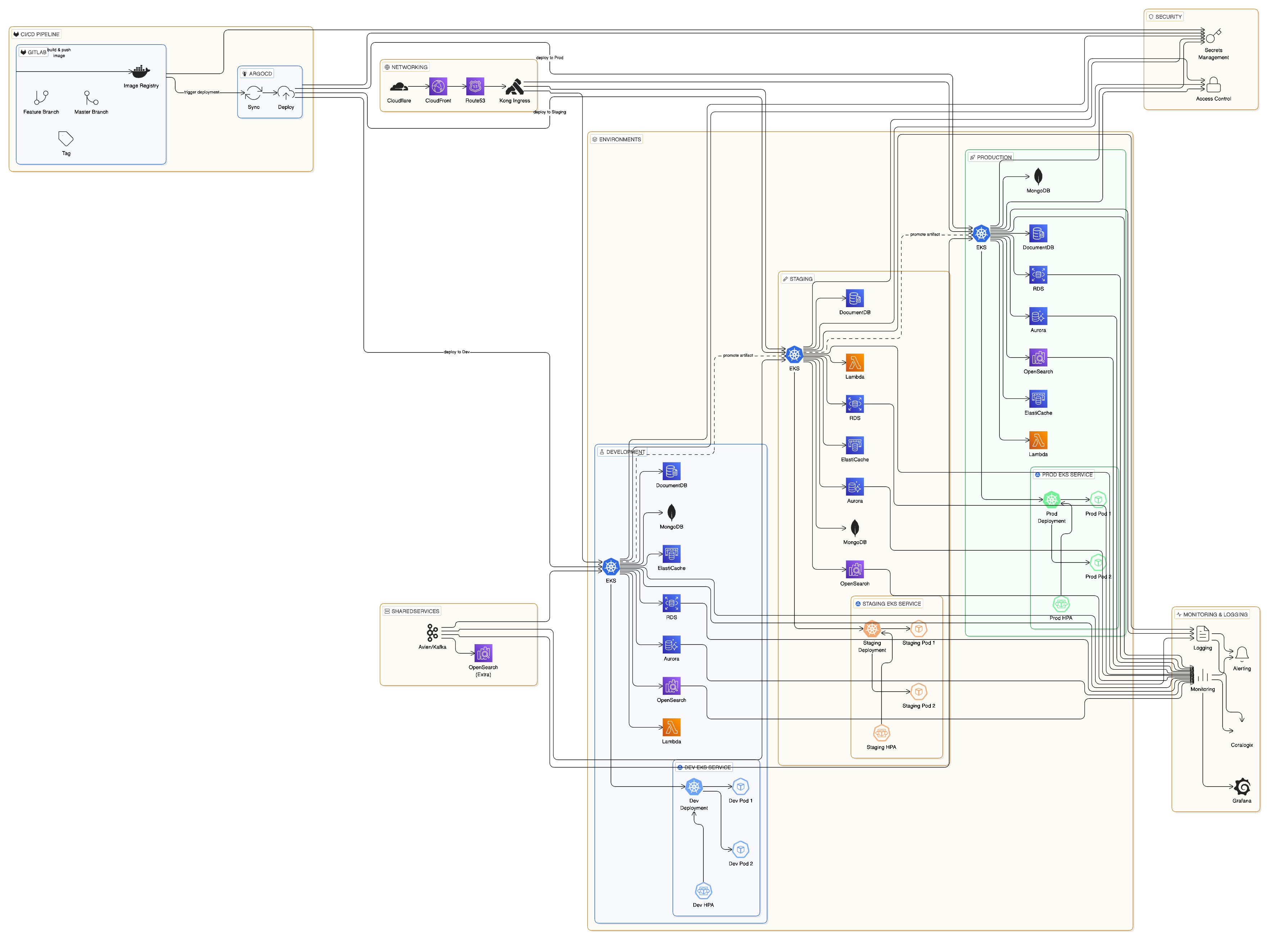
当社のプラットフォームは、AWS マネージドサービス、Kubernetes オーケストレーション、GitOps デプロイ手法を活用したモダンなクラウドネイティブ・アーキテクチャ上に構築されています。この**本番環境レベルのインフラストラクチャ**は、包括的な可観測性と自動スケーリングを備え、1 日あたり数百万件の API リクエストを処理しつつ、100ms 未満のレスポンス時間を維持します。
マルチ AZ 冗長構成による本番環境で実証された高い信頼性
Coralogix および Datadog によるリアルタイムな可観測性
インテリジェントなオートスケーリングによるゼロダウンタイムのデプロイ
 ***
***
## コアインフラ
### AWS クラウド基盤
当社のインフラストラクチャはすべて **Amazon Web Services (AWS)** 上で稼働しており、次の機能を活用しています:
フォールトトレランスを確保するため、複数のアベイラビリティーゾーンに分散配置されたサービス
厳格なセキュリティグループポリシーを適用した分離された Virtual Private Cloud (VPC)
ヘルスチェックと自動フェイルオーバー・ルーティング機能を備えたグローバル DNS
AWS 管理の Kubernetes コントロールプレーンによる 99.95% の SLA
### Kubernetes インフラストラクチャ
安全なデプロイと環境の分離を確保するために、**2つの専用 Kubernetes クラスター** を運用しています。
| Environment | Purpose | Deployment Flow |
| ---------------------- | ---------------------------- | ---------------------- |
| **Staging Cluster** | 開発者によるテスト、QA 検証、インテグレーションテスト | 検証のためにコード変更が最初にデプロイされる |
| **Production Cluster** | SLA 保証付きの本番顧客トラフィック | 検証済みのリリースのみが本番に昇格される |
#### 主要な Kubernetes コンポーネント
* **Karpenter** — 数分単位ではなく数秒で適切なサイズのコンピュートリソースをプロビジョニングする、AWS ネイティブなノード・オートスケーラー
* **Horizontal Pod Autoscaler (HPA)** — CPU、メモリ、およびカスタムメトリクスに基づいて Pod を自動的にスケーリング
* **Kong Gateway** — ingress/egress、レート制限、認証を処理するエンタープライズ向け API ゲートウェイ
* **ArgoCD** — 宣言的で監査可能なリリースを実現する、GitOps ベースのデプロイメントコントローラー
***
## API ゲートウェイとトラフィック管理
### Kong Gateway
すべてのAPIトラフィックは **Kong Gateway** を通過し、次の機能を提供します:
エッジ側でのAPIキー検証およびJWTトークンの検証
公平なリソース配分を保証するためのクライアントごとのリクエスト制限
正常に稼働しているサービスポッド間でのインテリジェントなトラフィック分散
すべてのトラフィックをTLS 1.3で暗号化し、証明書を自動更新
### Route 53 DNS
AWS Route 53 は次の機能を提供します:
* **グローバルなレイテンシベースのルーティング** — ユーザーを自動的に最速のエンドポイントにルーティング
* **ヘルスチェック** — 障害発生時の自動フェイルオーバーを伴う継続的な監視
* **100% 稼働 SLA** — DNS 解決に対する AWS による可用性保証
***
## CI/CD パイプライン
デプロイパイプラインでは、本番環境にコードをリリースする前に厳格な品質ゲートを設けています。
### 開発ワークフロー
```mermaid theme={null}
flowchart LR
A[Developer Commit] --> B[GitLab CI Pipeline]
B --> C{Linting & Tests}
C -->|Pass| D[Build Container Image]
C -->|Fail| E[Reject & Notify]
D --> F[Push to Registry]
F --> G[Peer Review Required]
G -->|2 Approvals| H[Update GitOps Repo]
H --> I[ArgoCD Sync]
I --> J[Deploy to Staging]
J -->|Validated| K[Promote to Production]
```
### パイプラインのステージ
| ステージ | 説明 | 品質ゲート |
| ----------------- | ------------------------------- | ------------------ |
| **Lint** | コードスタイルおよび静的解析チェック | すべてのルールに合格すること |
| **Unit Tests** | テストスイートの自動実行 | テスト 100% 成功 |
| **Security Scan** | コンテナ脆弱性スキャン | 重大/高リスクの CVE がないこと |
| **Build** | コミット SHA でタグ付けした Docker イメージの作成 | ビルド成功 |
| **Peer Review** | 2 名の開発者による手動でのコードレビュー | 2 名の承認が必要 |
| **GitOps Update** | ArgoCD リポジトリ内のイメージタグ更新 | 手動プロモーション |
### ArgoCD を用いた GitOps
すべてのデプロイは、GitOps の原則に従い **ArgoCD** によって管理されます:
* **宣言的** — 望ましい状態を Git 上で定義し、単一の信頼できる情報源とする
* **自動同期** — ArgoCD が変更を検知して自動的に適用する
* **ロールバック機能** — Git コミットを戻すことで即時にロールバック可能
* **監査証跡** — Git のコミットログによる完全なデプロイ履歴
本番環境へのすべての変更は、特定の Git コミット、ピアレビュー、および承認者に紐づけて追跡できるため、コンプライアンス要件に対する完全な監査性を確保できます。
***
## オートスケーリングアーキテクチャ
当社のインフラストラクチャは、トラフィックの急増に対応するため、複数のレベルで自動的にスケールします。
### Podレベルのスケーリング (HPA)
各サービスのデプロイには、Horizontal Pod Autoscaler (HPA) の設定が含まれています。
```yaml theme={null}
# HPA設定の例
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
spec:
minReplicas: 3
maxReplicas: 50
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
```
**スケーリング条件:**
* CPU 使用率 > 70%
* メモリ使用率 > 80%
* カスタムメトリクス(リクエストキュー長、レイテンシーのパーセンタイル値)
### ノードレベルのスケーリング(Karpenter)
**Karpenter** はクラスターのキャパシティを次のように管理します:
* 60秒以内に最適なサイズのノードをプロビジョニングする
* 活用率の低いノードを集約してコストを削減する
* 重要度の低いワークロード向けにスポットインスタンスをサポートする
* Pod のトポロジーおよびアベイラビリティゾーンの制約を考慮する
***
## 本番環境レベルのオブザーバビリティとモニタリング
当社のインフラストラクチャは、多層的なオブザーバビリティを備えた**エンタープライズグレードのモニタリング**を採用しており、システムの健全性、パフォーマンス、信頼性を完全に可視化できるようにしています。すべてのコンポーネントは、自動アラートとインシデント対応プロセスにより継続的に監視されています。
### 包括的な監視スタック
**分散トレーシングとログ監視**
* すべてのサービスからのリアルタイムなログ集約
* マイクロサービス間の分散トレーシング
* アプリケーション性能監視(APM)
* 相関IDを用いたエンドツーエンドのリクエスト追跡
* ログパターンの認識と異常検知
* ビジネスメトリクス向けのカスタムダッシュボード
**アラートとシンセティックモニタリング**
* 24時間365日の継続的なAPIエンドポイントテスト
* 複数リージョンでのシンセティックモニタリング
* レスポンスタイムと可用性の監視
* インテリジェントなルーティングによる自動アラート
* サービスレベル指標(SLI)の追跡
* パフォーマンス劣化の検知
### Coralogix: トレーシングとログ取得
Coralogix はアプリケーション層に対する**完全なオブザーバビリティ**を提供します。
すべてのサービス、Pod、およびコンテナからのアプリケーションログをリアルタイムに集約し、インフラ全体にわたるデバッグ情報へ即時にアクセス可能にします。
すべての API リクエストを、マイクロサービス、ロードバランサー、データベース、および外部サービスにまたがってエンドツーエンドでトレースします。これにより、パフォーマンス問題やエラーの根本原因を迅速に分析できます。
スタックトレース、コンテキスト情報、影響を受けたユーザー数を含む自動エラー検出を行います。エラーは重大度と影響度に基づいて分類されます。
すべてのサービスにわたる API レスポンスタイム、スループット、エラー率、およびリソース使用率に関するリアルタイムのメトリクスを提供します。
**本番環境における Coralogix の主な機能:**
* **保持ポリシー**: 即時アクセス用の 30 日間ホットストレージと、コンプライアンス対応のための 90 日間アーカイブ
* **クエリパフォーマンス**: 数十億件のログエントリに対してサブ秒レイテンシでのクエリ
* **アラート連携**: Slack チャンネルおよびオンコールエンジニアへの自動ルーティング
* **カスタムダッシュボード**: ビジネス固有のメトリクスをステークホルダーがリアルタイムに閲覧可能
### Datadog: アラートとシンセティック監視
Datadog は**プロアクティブな監視**と継続的な検証を提供します。
自動テストが複数の地理的リージョンから 60 秒ごとに実行され、顧客に影響が出る前に API の可用性、レスポンスタイム、データの正確性を検証します。
機械学習による異常検知がメトリクスにおける異常なパターンを特定し、問題が顧客に影響を与える前にアラートを発報します。
サービスレベル目標 (SLO) をリアルタイムで監視し、99.9% の可用性目標に対する自動レポートを生成します。
p50、p95、p99 レイテンシーのパーセンタイルを継続的に監視し、一貫したパフォーマンスを確保します。
**Datadog のシンセティックテストには以下が含まれます:**
| テスト種別 | 実行頻度 | リージョン | 監視メトリクス |
| --------------- | ------ | ------------- | -------------------------------- |
| **API ヘルスチェック** | 60 秒ごと | グローバル 5 リージョン | 可用性、レスポンスタイム、ステータスコード |
| **データ精度テスト** | 5 分ごと | 3 リージョン | データ鮮度、スキーマバリデーション、整合性 |
| **パフォーマンステスト** | 60 秒ごと | 5 リージョン | レイテンシー (p50/p95/p99)、スループット、エラー率 |
| **認証テスト** | 5 分ごと | 2 リージョン | API キー検証、レート制限、OAuth フロー |
### Slack 連携とインシデント管理
すべての監視システムは、即時の可視性と迅速な対応のために、**専用の Slack チャンネル** と連携しています:
**クリティカルアラート**
* 即時対応が必要な P1/P2 インシデント
* オンコールエンジニアへの自動ページング
* リアルタイムメトリクスとランブックへのリンク
* インシデントコマンダーの割り当て
**パフォーマンスインサイト**
* 日次ヘルス状況サマリー
* キャパシティプランニング用アラート
* パフォーマンストレンド通知
* 異常検知の警告
**Slack アラートワークフロー:**
```mermaid theme={null}
flowchart LR
A[アラート発生] --> B{重大度レベル}
B -->|P1/P2| C[#alerts-production]
B -->|P3/P4| D[#monitoring-insights]
C --> E[オンコールエンジニアに通知]
C --> F[インシデントチャネル作成]
F --> G[開発者アサイン]
G --> H[根本原因調査]
H --> I[修正デプロイ]
I --> J[事後分析レポート]
```
### アラートとインシデント
**開発者アサインのプロセス:**
1. **アラート検知** → コンテキストとメトリクス付きの自動 Slack 通知
2. **オンコールエンジニアによるトリアージ** → 重大度を評価し、インシデント用チャンネルを作成
3. **開発者アサイン** → 影響を受けたサービスに基づき、担当の専門エンジニアをタグ付け
4. **調査** → Coralogix のトレースと Datadog のメトリクスを用いた根本原因分析
5. **解決** → 標準的な GitOps パイプラインを通じて修正をデプロイ
6. **ポストモーテム** → インシデントを文書化し、再発防止策を定義
すべての P1/P2 インシデントは、平日 24 時間体制で待機しているオンコールエンジニアに対して、**即時の自動ページング**を行います。
当社のモニタリングシステムは、プロアクティブなアラートと自動復旧により、**潜在的な問題の 95% を顧客影響前に検出・解決**しています。
***
## セキュリティとコンプライアンス
### ネットワークセキュリティ
* **VPC 分離** — パブリックインターネットからの完全なネットワーク分離
* **セキュリティグループ** — 厳格なインバウンド/アウトバウンドルール、デフォルト拒否ポリシー
* **TLS の徹底適用** — すべての内部・外部トラフィックを暗号化
* **シークレット管理** — 機密性の高い認証情報を AWS Secrets Manager で管理
### アクセス制御
* **RBAC** — すべての操作に対する Kubernetes ロールベースのアクセス制御
* **SSO 統合** — エンタープライズ向け ID プロバイダーとの統合
* **監査ログ** — コンプライアンス対応のために保持される完全なアクセスログ
***
## 災害復旧
### 復旧目標
| 指標 | 目標 | 現状 |
| ---------------------------------- | ----- | ---------------- |
| **RTO** (Recovery Time Objective) | 15分未満 | 約5分 |
| **RPO** (Recovery Point Objective) | 1分未満 | リアルタイムでのレプリケーション |
### レジリエンス機能
* **マルチ AZ レプリケーション** — 可用性ゾーン間でのデータ複製
* **自動フェイルオーバー** — Route 53 のヘルスチェックによって DNS フェイルオーバーを実行
* **ローリングデプロイ** — ゼロダウンタイムでのデプロイと自動ロールバック
* **バックアップとリストア** — ポイントインタイムリカバリ対応の自動日次バックアップ
***
## 本番環境対応の信頼性保証
### なぜ当社のインフラは堅牢なのか
Benzinga のインフラは、**大規模な本番環境で検証済み**であり、実運用で日次数百万件のリクエストを高い信頼性で処理しています。
**本番環境での実績**
* 1,000 万件超の API リクエストを日次処理
* 平均レスポンスタイム 100ms 未満
* 稼働率 99.9% を達成
* 3 年超にわたりデータ損失ゼロ
**運用面での卓越性**
* 24/5/365 のオンコールエンジニア体制
* 自動フェイルオーバーとセルフヒーリング
* 複数リージョンによる冗長構成
### モニタリングとオブザーバビリティの徹底
当社の**包括的なモニタリング**により、問題はお客様のビジネスへ影響が及ぶ前に検知・解決されます。
すべてのリクエスト、ログエントリ、メトリクスを、Coralogix の分散トレーシングと集中ログ管理を用いてエンドツーエンドで追跡します
Datadog のシンセティックモニタリングにより、複数リージョンから 60 秒ごとに API をテストし、お客様への影響が出る前に問題をアラートします
自動化された Slack 連携により、アラートを専用チャンネルへルーティングし、開発者の即時アサインと解決状況のトラッキングを行います
すべてのインシデントに対してポストモーテム分析を行い、自動化された予防措置によって問題が再発しないようにします
### クライアントからの信頼: それがお客様にもたらすもの
Benzinga の API と連携することで、次のような仕組みによって支えられた **本番環境対応のインフラストラクチャ** に接続できます。
| 機能 | クライアント側のメリット |
| ---------------- | ------------------------------------------ |
| **マルチAZ冗長構成** | AWS アベイラビリティーゾーン障害時でも、アプリケーションはオンラインを維持します |
| **自動スケーリング** | トラフィック急増時でも、レート制限にかかることなくシームレスにリクエストを処理します |
| **24/7 監視** | お客様が性能低下に気付く前に、エンジニアが問題を検知して解決します |
| **ゼロダウンタイムデプロイ** | アップデートによってサービスの可用性が中断されることはありません |
| **完全な監査証跡** | すべてのデプロイを追跡・レビューし、即時にロールバック可能です |
| **プロアクティブなアラート** | 潜在的な問題の 95% を、顧客への影響前に解決します |
**本番運用対応**: 当社のインフラストラクチャは、可用性 99.9% を維持しつつ、リアルタイム金融データ配信で 100ms 未満のレイテンシを保ちながら、これまでに **数十億件の API リクエスト** を処理してきました。
***
## 概要
Benzinga のインフラストラクチャは、次の要素により **エンタープライズグレードの信頼性** を提供します。
AWS EKS を用いたマルチ AZ デプロイとマネージドコントロールプレーンにより、最大限の稼働時間を確保します
ArgoCD によるリリース管理で、完全な監査証跡と即時ロールバック機能を提供します
Karpenter と HPA によるシームレスなキャパシティ管理で、トラフィックのスパイクを自動的に処理します
Coralogix によるトレース/ログと Datadog によるアラート/シンセティクス、さらに Slack 連携により、迅速なインシデント対応を実現します
専任のオンコールエンジニアが対応にあたります
暗号化、RBAC、ネットワーク分離による多層防御で、お客様のデータを保護します
**お客様の成功が最優先です**: インフラストラクチャ、SLA 保証、またはお客様固有の信頼性要件についてご質問やご相談がある場合は、アカウント担当者までお問い合わせいただくか、[support@benzinga.com](mailto:support@benzinga.com) までメールでご連絡ください。