Benzinga’s infrastructure is designed for 99.9% availability, ensuring your applications receive reliable, real-time financial data around the clock. Our production environment is battle-tested, fully monitored, and backed by 24/5 on-call engineering support.
Overview
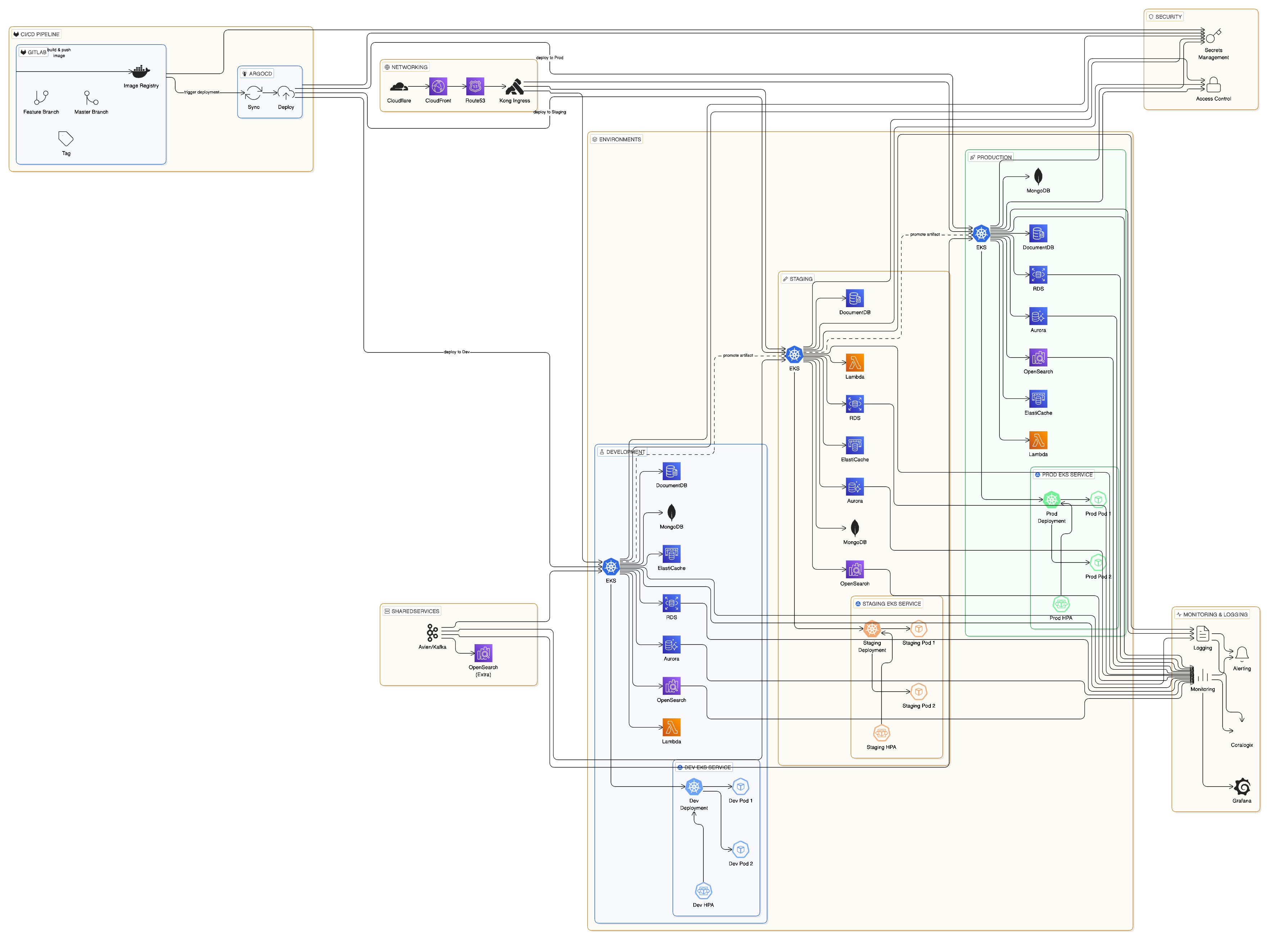
Our platform is built on a modern, cloud-native architecture leveraging AWS managed services, Kubernetes orchestration, and GitOps deployment practices. This production-grade infrastructure powers millions of API requests daily while maintaining sub-100ms response times with comprehensive observability and automated scaling.99.9% Uptime SLA
Production-tested reliability with multi-AZ redundancy
24/7 Monitoring
Real-time observability with Coralogix and Datadog
Automated Scaling
Zero-downtime deployments with intelligent autoscaling
Core Infrastructure
AWS Cloud Foundation
Our infrastructure runs entirely on Amazon Web Services (AWS), taking advantage of:Multi-AZ Deployment
Services deployed across multiple Availability Zones for fault tolerance
AWS VPC
Isolated Virtual Private Cloud with strict security group policies
Route 53
Global DNS with health checks and automatic failover routing
Managed EKS
AWS-managed Kubernetes control plane with 99.95% SLA
Kubernetes Infrastructure
We operate two dedicated Kubernetes clusters to ensure safe deployments and environment isolation:Key Kubernetes Components
- Karpenter — AWS-native node autoscaler that provisions right-sized compute in seconds, not minutes
- Horizontal Pod Autoscaler (HPA) — Automatic pod scaling based on CPU, memory, and custom metrics
- Kong Gateway — Enterprise API gateway handling ingress/egress, rate limiting, and authentication
- ArgoCD — GitOps-based deployment controller for declarative, auditable releases
API Gateway & Traffic Management
Kong Gateway
All API traffic flows through Kong Gateway, providing:1
Authentication
API key validation and JWT token verification at the edge
2
Rate Limiting
Per-client request throttling to ensure fair resource allocation
3
Load Balancing
Intelligent traffic distribution across healthy service pods
4
SSL/TLS Termination
All traffic encrypted with TLS 1.3, certificates auto-renewed
Route 53 DNS
AWS Route 53 provides:- Global latency-based routing — Users automatically routed to the fastest endpoint
- Health checks — Continuous monitoring with automatic failover on failure
- 100% uptime SLA — AWS-backed availability guarantee for DNS resolution
CI/CD Pipeline
Our deployment pipeline enforces strict quality gates before any code reaches production.Development Workflow
Pipeline Stages
GitOps with ArgoCD
All deployments are managed through ArgoCD, following GitOps principles:- Declarative — Desired state defined in Git, single source of truth
- Automated sync — ArgoCD detects changes and applies them automatically
- Rollback capability — Instant rollback by reverting Git commits
- Audit trail — Complete deployment history via Git commit log
Auto-Scaling Architecture
Our infrastructure scales automatically at multiple levels to handle traffic spikes.Pod-Level Scaling (HPA)
Each service deployment includes Horizontal Pod Autoscaler configuration:- CPU utilization > 70%
- Memory utilization > 80%
- Custom metrics (request queue depth, latency percentiles)
Node-Level Scaling (Karpenter)
Karpenter handles cluster capacity by:- Provisioning optimally-sized nodes in under 60 seconds
- Consolidating underutilized nodes to reduce costs
- Supporting spot instances for non-critical workloads
- Respecting pod topology and availability zone constraints
Production-Grade Observability & Monitoring
Our infrastructure employs enterprise-grade monitoring with multiple layers of observability, ensuring complete visibility into system health, performance, and reliability. Every component is continuously monitored with automated alerting and incident response protocols.Comprehensive Monitoring Stack
Coralogix
Distributed Tracing & Logging
- Real-time log aggregation from all services
- Distributed tracing across microservices
- Application performance monitoring (APM)
- End-to-end request tracking with correlation IDs
- Log pattern recognition and anomaly detection
- Custom dashboards for business metrics
Datadog
Alerting & Synthetic Monitoring
- 24/7 continuous API endpoint testing
- Multi-region synthetic monitoring
- Response time and availability tracking
- Automated alerts with intelligent routing
- Service-level indicator (SLI) tracking
- Performance regression detection
Coralogix: Tracing & Logging
Coralogix provides complete observability into our application layer:1
Centralized Logging
All application logs from every service, pod, and container are aggregated in real-time, providing instant access to debugging information across the entire infrastructure.
2
Distributed Tracing
Every API request is traced end-to-end across microservices, load balancers, databases, and external services. This enables rapid root-cause analysis of performance issues or errors.
3
Error Tracking
Automatic error detection with stack traces, contextual information, and affected user counts. Errors are categorized by severity and impact.
4
Performance Analytics
Real-time metrics on API response times, throughput, error rates, and resource utilization across all services.
- Retention Policy: 30-day hot storage for immediate access, 90-day archive for compliance
- Query Performance: Sub-second queries across billions of log entries
- Alert Integration: Automated routing to Slack channels and on-call engineers
- Custom Dashboards: Business-specific metrics visible to stakeholders in real-time
Datadog: Alerting & Synthetics
Datadog provides proactive monitoring and continuous validation:1
Synthetic API Testing
Automated tests run every 60 seconds from multiple geographic regions, validating API availability, response times, and data accuracy before customers are impacted.
2
Intelligent Alerting
Machine learning-powered anomaly detection identifies unusual patterns in metrics, triggering alerts before issues impact customers.
3
SLA Monitoring
Real-time tracking of service-level objectives (SLOs) with automated reporting on 99.9% availability targets.
4
Performance Benchmarking
Continuous monitoring of p50, p95, and p99 latency percentiles to ensure consistent performance.
Slack Integration & Incident Management
All monitoring systems integrate with dedicated Slack channels for immediate visibility and rapid response:#alerts-production
Critical Alerts
- P1/P2 incidents requiring immediate action
- Automated on-call engineer paging
- Real-time metrics and runbook links
- Incident commander assignment
#monitoring-insights
Performance Insights
- Daily health summaries
- Capacity planning alerts
- Performance trend notifications
- Anomaly detection warnings
Alerting & Incidents
Developer Assignment Process:- Alert Triggered → Automatic Slack notification with context and metrics
- On-Call Engineer Triaged → Severity assessed, incident channel created
- Developer Assigned → Subject matter expert tagged based on affected service
- Investigation → Root cause analysis using Coralogix traces and Datadog metrics
- Resolution → Fix deployed through standard GitOps pipeline
- Post-Mortem → Incident documented with preventive measures
Security & Compliance
Network Security
- VPC Isolation — Complete network segmentation from public internet
- Security Groups — Strict ingress/egress rules, deny-by-default
- TLS Everywhere — All internal and external traffic encrypted
- Secrets Management — AWS Secrets Manager for sensitive credentials
Access Control
- RBAC — Kubernetes role-based access control for all operations
- SSO Integration — Enterprise identity provider integration
- Audit Logging — Complete access logs retained for compliance
Disaster Recovery
Recovery Objectives
Resilience Features
- Multi-AZ replication — Data replicated across availability zones
- Automated failover — Route 53 health checks trigger DNS failover
- Rolling deployments — Zero-downtime deployments with automatic rollback
- Backup & restore — Automated daily backups with point-in-time recovery
Production-Ready Reliability Guarantees
Why Our Infrastructure is Rock-Solid
Benzinga’s infrastructure is production-tested at scale, handling millions of daily requests with proven reliability:Battle-Tested at Scale
Production Statistics
- 10M+ API requests processed daily
- Sub-100ms average response time
- 99.9% historical uptime achieved
- Zero data loss in 3+ years
Enterprise-Grade Operations
Operational Excellence
- 24/5/365 on-call engineering coverage
- Automated failover and self-healing
- Multi-region redundancy
Monitoring & Observability Excellence
Our comprehensive monitoring ensures issues are detected and resolved before they impact your business:1
Complete Visibility
Every request, log entry, and metric is tracked end-to-end using Coralogix distributed tracing and centralized logging
2
Proactive Detection
Datadog synthetic monitoring tests APIs every 60 seconds from multiple regions, alerting on issues before customer impact
3
Rapid Response
Automated Slack integration routes alerts to dedicated channels with immediate developer assignment and resolution tracking
4
Continuous Improvement
Post-mortem analysis for all incidents ensures issues never recur with automated preventive measures
Client Confidence: What This Means for You
When you integrate with Benzinga’s APIs, you’re connecting to a production-grade infrastructure backed by:Production-Ready: Our infrastructure has processed over Billion API requests with 99.9% availability and maintains sub-100ms latency for real-time financial data delivery.
Summary
Benzinga’s infrastructure delivers enterprise-grade reliability through:1
Cloud-Native Architecture
AWS EKS with multi-AZ deployment and managed control plane ensuring maximum uptime
2
GitOps Deployments
ArgoCD-managed releases with full audit trail and instant rollback capabilities
3
Intelligent Auto-Scaling
Karpenter + HPA for seamless capacity management handling traffic spikes automatically
4
World-Class Monitoring
Coralogix tracing/logging + Datadog alerting/synthetics with Slack integration for rapid incident response
5
24/5 Operations
Dedicated on-call engineers
6
Strict Security
Defense-in-depth with encryption, RBAC, and network isolation protecting your data
Your Success is Our Priority: For questions about our infrastructure, SLA guarantees, or to discuss your specific reliability requirements, contact your account representative or email support@benzinga.com.